Mobile devices, Webpage, Internet, HTML, Javascript, Customized software, 2019
Project Description
RECEITER(s) imagines a machine version of recitation practice. The system consists of mobile devices, voice assistants, and Web applications. It generates and reconstructs sentences from Web-related texts, searching trends, and netizen comments. The connected devices repeat all the words afterward with built-in voice assistants. The viewer’s mobile device can join the recitation practice by opening a webpage. Establishing connections between the functionality and performativity of networked entities provides clues to the promise, circumstance, success and failures, and the adaptive capacity of the Internet.
Cisco company introduced a commercial series, “Empowering the Internet Generation,” with images of conventional transportation and multiracial students prancing around to ask the viewer: “Are you ready?” in 2000, prompting the Internet to be desirable before the dot-com bubble burst. Today, numerous accents are designed to represent races and citizenships in our voice assistants for users to choose from. These synthesis voices were by-products when the Internet expanded its territory. They have embedded in our lives and move from the new to the habitual at the edge of obsolescence. Our machines intend to become more like us and vice versa. Meanwhile, on the Web, the analytic, creative, and commercial efforts focus exclusively on figuring out what will spread and who will spread it the fastest. But what do we miss in this constant push to the future?

Any mobile device opening project webpage will join the recitation with a voice assistant name and scripts show on the screen.


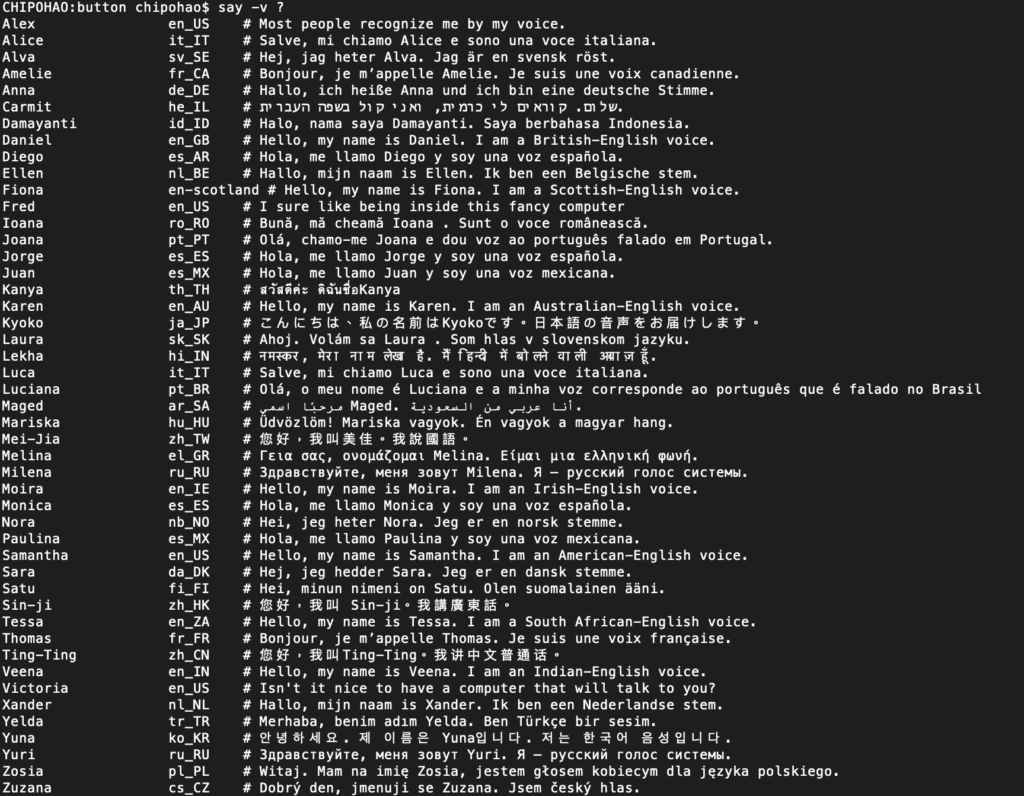
List of voice assistant build in OSX system with various accents.